
Claude の知能を使いこなす
Anthropic の共同創業者の 1 人である Chris Olah は、Claude のような生成 AI システムは「作られる」よりも「育てられる」に近いと述べています。研究者は成長の方向を定める条件を設定しますが、そこから現れる正確な構造や能力は、必ずしも予測可能ではありません。
これは Claude を使ってものを作る人にとっての課題を生みます——エージェントハーネスは Claude が単独ではできないことの仮定を符号化しますが、Claude が賢くなるにつれてそれらの仮定は古びていきます。この記事のような場所で共有された学びさえも、頻繁な見直しに値します。
この記事では、Claude の進化する知能に追いつきながらレイテンシとコストのバランスをとるアプリケーションを作るとき、チームが使うべき 3 つのパターンを共有します——「Claude がすでに知っていることを使う」「やめられることは何かを問う」「エージェントハーネスで境界を注意深く設定する」の 3 つです。
1. Claude が知っていることを使う
アプリケーションを作るときは、Claude がよく理解しているツールを使うことをお勧めします。
2024 年後半、Claude 3.5 Sonnet は SWE-bench Verified で 49% に達しました——当時の最先端です。使ったのはファイルの閲覧・作成・編集のための bash ツールとテキストエディタツールだけです。Claude Code もこれらのツールの上に立脚しています。Bash はエージェント構築のために設計されたわけではありませんが、Claude が 知っている ツールであり、使い方も時間とともに上達していきます。
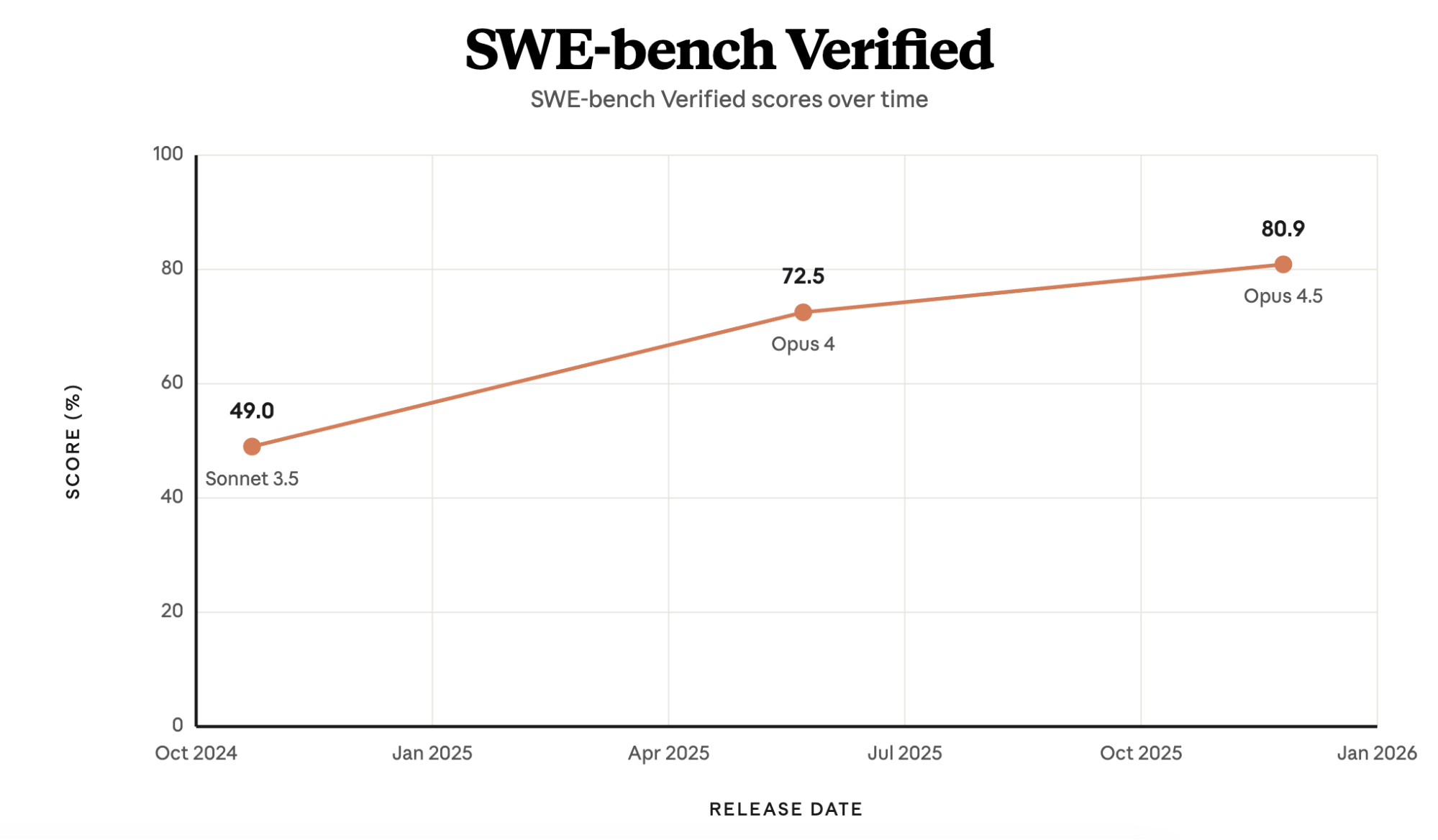
SWE-bench Verified ベンチマークにおける Claude モデル各世代のスコアの推移。
私たちは Claude がこれらの汎用ツールを組み合わせて、さまざまな問題を解くパターンを作り出すのを見てきました。たとえば Agent Skills、プログラマティックツール呼び出し、そしてメモリツールは、どれも bash とテキストエディタの 2 つのツールの上に構築されています。
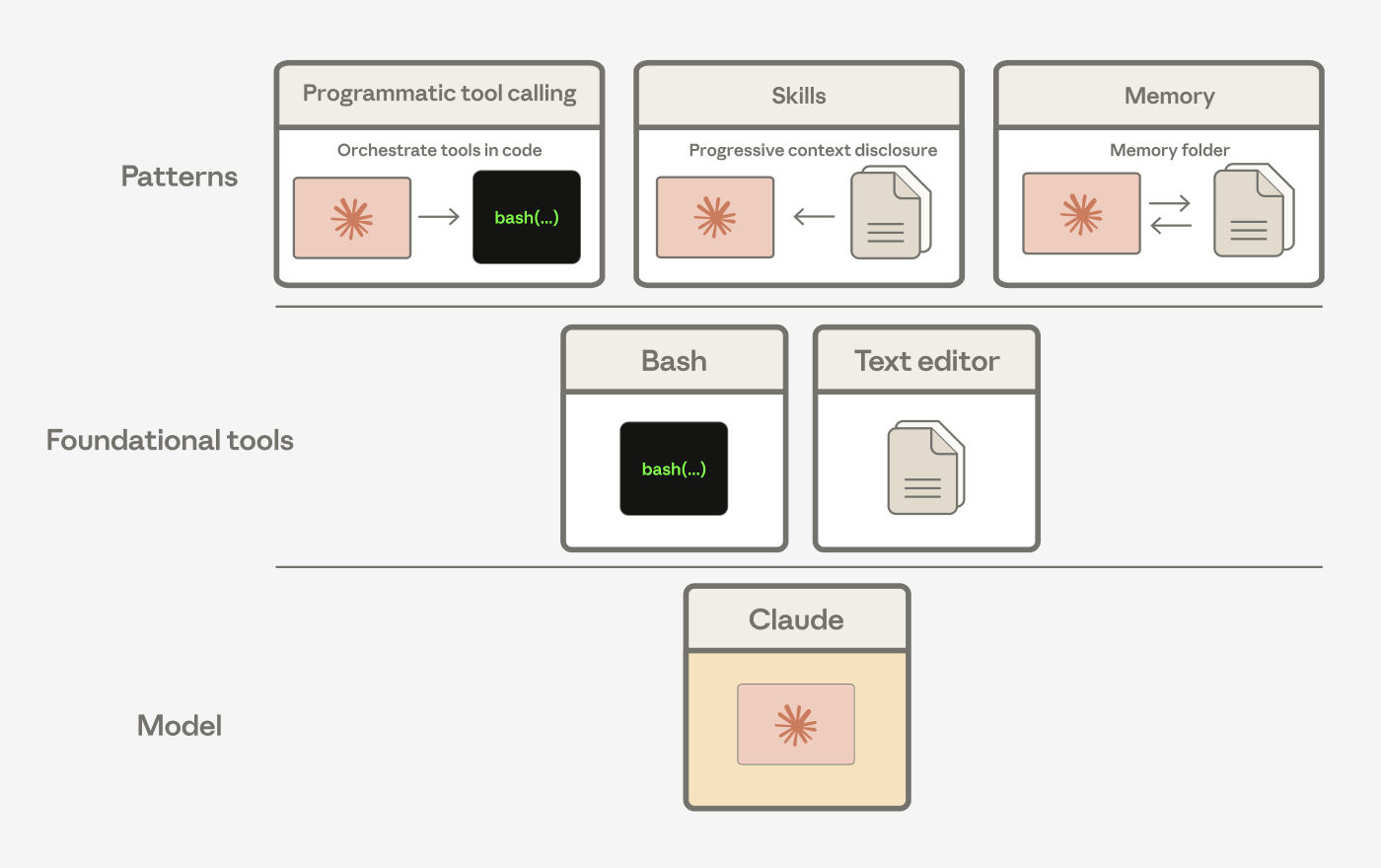
プログラマティックツール呼び出し、skills、memory は bash とテキストエディタツールの組み合わせから構成されている。
2. 「やめられることは何か」を問う
エージェントハーネスは、Claude が単独ではできないことの仮定を符号化します。Claude がより賢くなるにつれて、それらの仮定はテストされるべきです。
Claude に自分のアクションをオーケストレーションさせる
よくある仮定は、すべてのツール結果が Claude のコンテキストウィンドウを通じて流れ、次のアクションに情報を与えるべきというものです。ツール結果をトークンとして処理するのは、遅く、高コストで、そして——それが単に次のツールに渡されるだけであったり、Claude が出力のごく一部にしか興味がなかったりする場合には——不要です。
単一の列について推論するために大きなテーブルを読むことを考えてみてください——テーブル全体がコンテキストに入り、Claude は必要のないすべての行についてトークンコストを払います。これはハードコードされたフィルタを使って、ツール設計で対処することもできます。しかし、これではエージェントハーネスが オーケストレーション判断 を下してしまっているという事実に対応できません——Claude のほうが、その判断により適した立場にいるのです。
Claude にコード実行ツール (たとえば bash ツール や言語特化型の REPL) を与えることで、これが解決されます——Claude がツール呼び出しとその間のロジックをコードで表現できるようになるからです。ハーネスがすべてのツール呼び出し結果をトークンとして処理すると決めるのではなく、Claude が、どの結果を通過させ、フィルタし、あるいは次の呼び出しにパイプするかを、コンテキストウィンドウに触れることなく決定します。Claude のコンテキストウィンドウに到達するのは、コード実行の出力だけです。
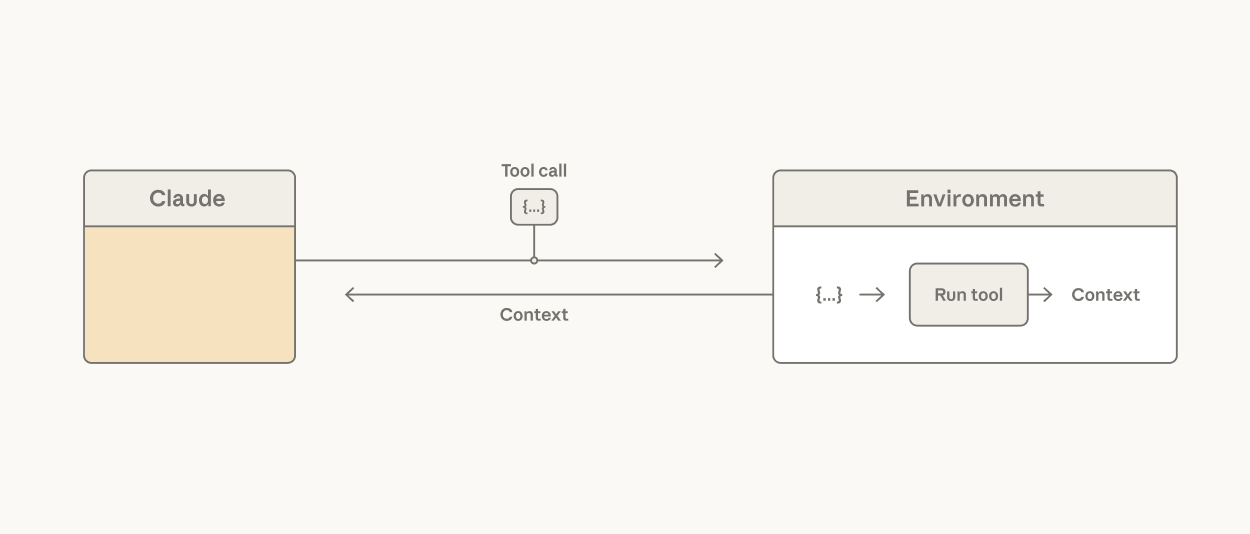
Claude はツールを呼び出し、それらは環境の中で実行される。
オーケストレーションの決定がハーネスからモデルへと移ります。コードは Claude がアクションをオーケストレーションする一般的な方法なので、強いコーディングモデルは強い 汎用 エージェントでもあります。このパターンを使うことで、Claude はコーディング以外の eval でも強いパフォーマンスを示します——エージェントがウェブを閲覧する能力を測るベンチマークである BrowseComp では、Opus 4.6 に自身のツール出力をフィルタする能力を与えたところ、精度は 45.3% から 61.6% に上昇しました。
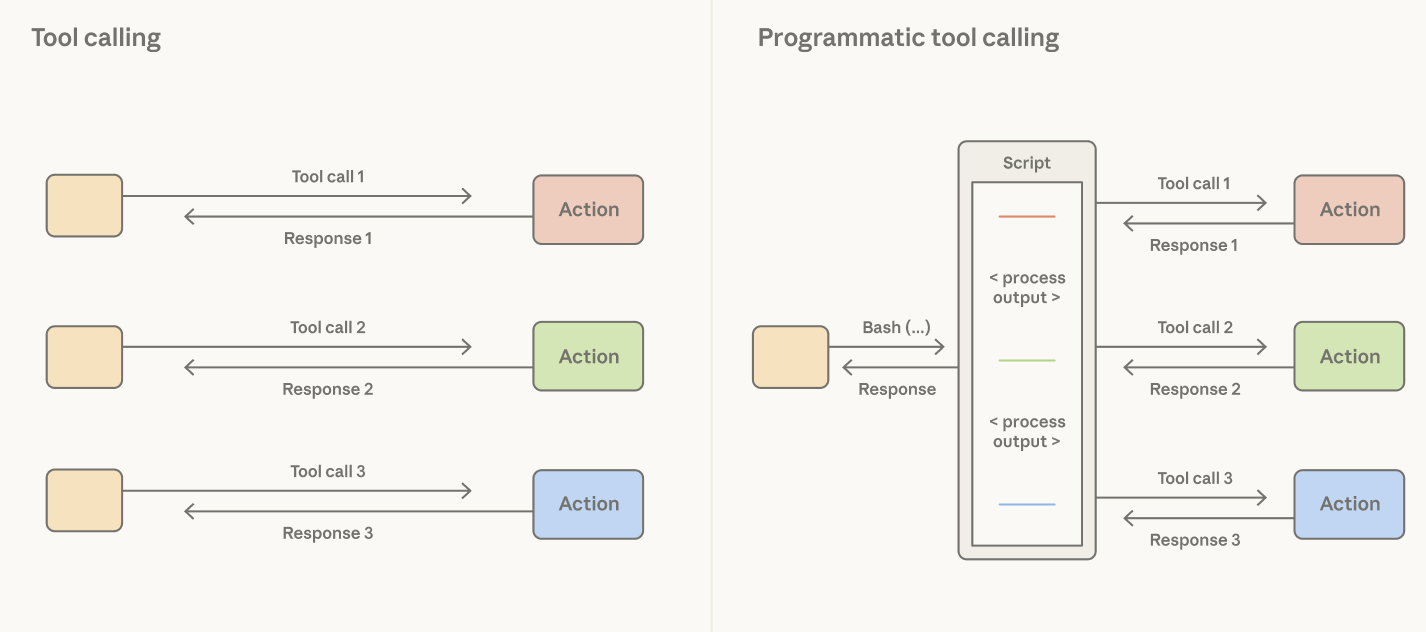
Claude はツール呼び出しとその間のロジックを表現するコードを書ける。
Claude に自分のコンテキストを管理させる
タスク固有のコンテキストが、bash やテキストエディタツールといった汎用ツールの使い方を方向づけます。よくある仮定は、システムプロンプトにタスク固有の指示を手作りで詰め込むべき、というものです。問題は、事前に指示を詰め込んだプロンプトは多数のタスクにまたがるとスケールしないということです——追加されるトークンごとに Claude の注意の予算が消費されますし、めったに使われない指示でコンテキストを事前にロードするのは無駄です。
Claude にスキルへのアクセスを与えることが、これに対処します——各スキルの YAML フロントマターは短い説明文で、コンテキストウィンドウに事前にロードされ、スキル内容の概要を提供します。タスクが必要とするなら、Claude がファイル読み取りツールを呼ぶことで、スキル全体を段階的に開示 (progressive disclosure) できます。
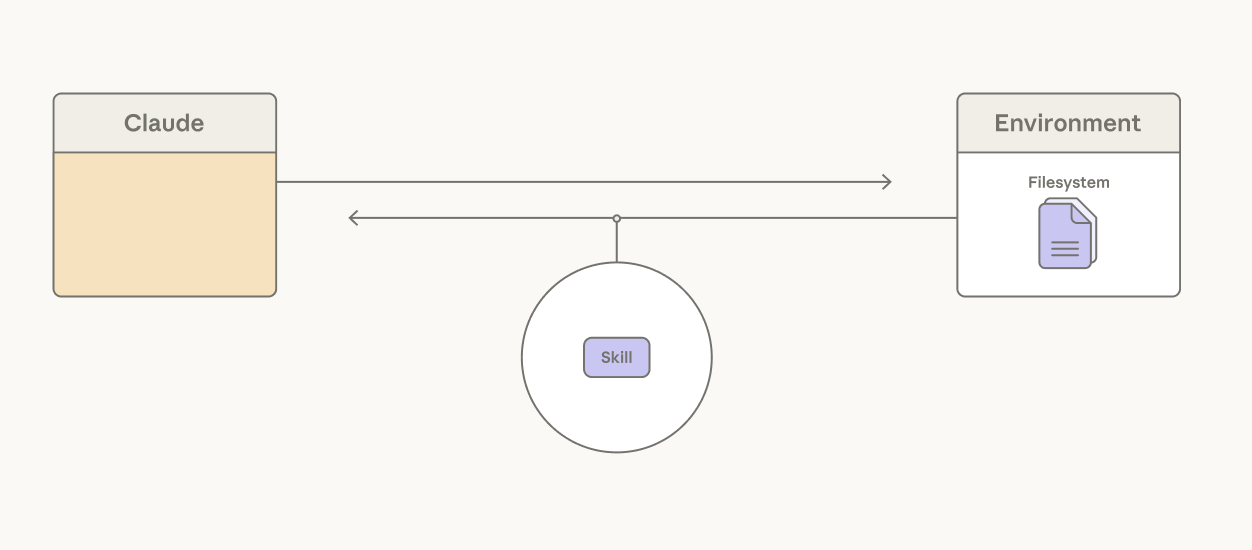
Claude はスキルを使ってタスクに関連するコンテキストを段階的に開示できる。
スキルが Claude に自分のコンテキストウィンドウを組み立てる自由を与えるのに対し、コンテキスト編集はその逆で、古くなったり関連性がなくなったりしたコンテキスト——古いツール結果や thinking ブロックなど——を選択的に削除する方法を提供します。
サブエージェントを使えば、Claude は特定のタスクに関する作業を隔離するため、新しいコンテキストウィンドウへフォークするタイミングを判断するのが上手くなっています。Opus 4.6 では、サブエージェントを生成する能力によって BrowseComp の成績が最良のシングルエージェント実行よりも 2.8% 改善しました。
Claude に自分のコンテキストを永続化させる
長時間動作するエージェントは、単一のコンテキストウィンドウの上限を超えることがあります。よくある仮定は、メモリシステムはモデル周辺の検索インフラに頼るべき、というものです。私たちの仕事の多くは、何を永続化するかを Claude 自身に 自分で選ばせる シンプルな方法を与えることに焦点を当ててきました。
たとえば、コンパクションは、長期タスクで連続性を保つために Claude が過去のコンテキストを要約することを可能にします。複数のリリースにわたって、Claude は何を覚えるべきかを選ぶのが上手くなってきました。エージェント型検索タスクである BrowseComp で見ると、Sonnet 4.5 はどれだけコンパクションの予算を与えても 43% で横ばいでした。しかし同じセットアップで、Opus 4.5 は 68% に、Opus 4.6 は 84% までスケールしました。
メモリフォルダはまた別のアプローチで、Claude がコンテキストをファイルに書き込み、後で必要に応じて読み取れるようにします。私たちはエージェント型検索にこれを使う Claude を見てきました。BrowseComp-Plus において、Sonnet 4.5 にメモリフォルダを与えることで精度が 60.4% から 67.2% に上がりました。
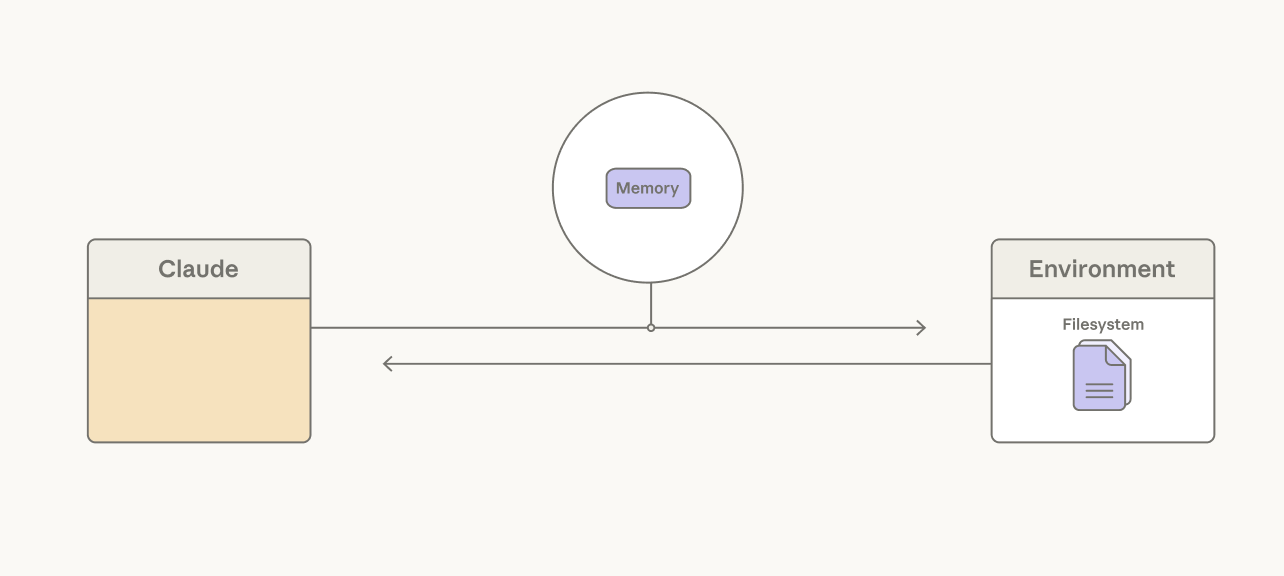
Claude はコンテキストをメモリフォルダに永続化できる。
ポケモンのような長時間ゲームは、Claude のメモリフォルダ利用能力の改善例です。Sonnet 3.5 はメモリを議事録のように扱い、重要なことではなく NPC が何を言ったかを書き留めていました。14,000 ステップ経っても 31 個のファイルを作り——そのうち 2 つはほとんど重複した毛虫ポケモンの情報——まだ 2 つ目の町にいました。
caterpie_weedle_info:
- Caterpie and Weedle are both caterpillar Pokémon.
- Caterpie is a caterpillar Pokémon that does not have poison.
- Weedle is a caterpillar Pokémon that does have poison.
- This information is crucial for future encounters and battles.
- If our Pokémon get poisoned, we should seek healing at a Pokémon
Center as soon as possible.
後のモデルは戦術的なノートを書きました。Opus 4.6 は同じステップ数で、ディレクトリに整理された 10 個のファイル、3 つのジムバッジ、そして自分自身の失敗から抽出した学びのファイルを持っていました。
/gameplay/learnings.md:
- Bellsprout Sleep+Wrap combo: KO FAST with BITE before Sleep
Powder lands. Don't let it set up!
- Gen 1 Bag Limit: 20 items max. Toss unneeded TMs before dungeons.
- Spin tile mazes: Different entry y-positions lead to DIFFERENT
destinations. Try ALL entries and chain through multiple pockets.
- B1F y=16 wall CONFIRMED SOLID at ALL x=9-28 (step 14557)
3. 境界を注意深く設定する
エージェントハーネスは、UX、コスト、セキュリティを強制するために Claude の周囲に構造を提供します。
キャッシュヒットを最大化するようにコンテキストを設計する
Messages API はステートレスです。Claude は過去のターンの会話履歴を見られません。つまりエージェントハーネスは、各ターンで新しいコンテキストを、過去のすべてのアクション、ツール説明、指示と一緒にパッケージ化して Claude に渡す必要があります。
プロンプトは設定されたブレークポイントに基づいてキャッシュできます。つまり、Claude API はブレークポイントまでのコンテキストをキャッシュに書き込み、そのコンテキストが過去のキャッシュエントリと一致するかチェックします。
キャッシュされたトークンはベース入力トークンのコストの 10% なので、エージェントハーネスでキャッシュヒットを最大化するための原則をいくつか挙げます。
| 原則 | 説明 |
|---|---|
| 静的なものを先に、動的なものを最後に | リクエストは、安定したコンテンツ (システムプロンプト、ツール) が先に来るように並べる。 |
| 更新はメッセージで | プロンプトを編集するのではなく、メッセージに <system-reminder> を追加する。 |
| モデルを切り替えない | セッション中にモデルを切り替えるのを避ける。キャッシュはモデル固有で、切り替えると壊れる。もしより安価なモデルが必要なら、サブエージェントを使う。 |
| ツールを注意深く管理する | ツールはキャッシュされたプレフィックスの中に置かれる。追加や削除は無効化を招く。動的な発見には tool search を使う——追加しつつキャッシュを壊さない。 |
| ブレークポイントを更新する | マルチターンのアプリケーション (たとえばエージェント) では、キャッシュを最新に保つために、ブレークポイントを最新のメッセージに移動する。これには auto-caching を使う。 |
UX・可観測性・セキュリティの境界には宣言的ツールを使う
Claude は必ずしもアプリケーションのセキュリティ境界や UX サーフェスを知っているわけではありません。Claude はツール呼び出しを生成し、それをハーネスが処理します。bash ツールは Claude にアクションを実行する広範なプログラマティック・レバレッジを与えますが、ハーネスに渡すのはコマンド文字列だけ——どんなアクションでも同じ形です。アクションを専用ツールに昇格させると、ハーネスは型付きの引数を持つアクション固有のフックを得られ、傍受、ゲート、レンダリング、監査が可能になります。
セキュリティ境界が必要なアクションは、専用ツールの自然な候補です。可逆性は良い基準であることが多く、外部 API 呼び出しのような戻しにくいアクションは、ユーザー確認でゲートできます。edit のような書き込みツールは、Claude が最後に読んでから変更されたファイルを上書きしないよう、ステイルネスチェックを含めることができます。
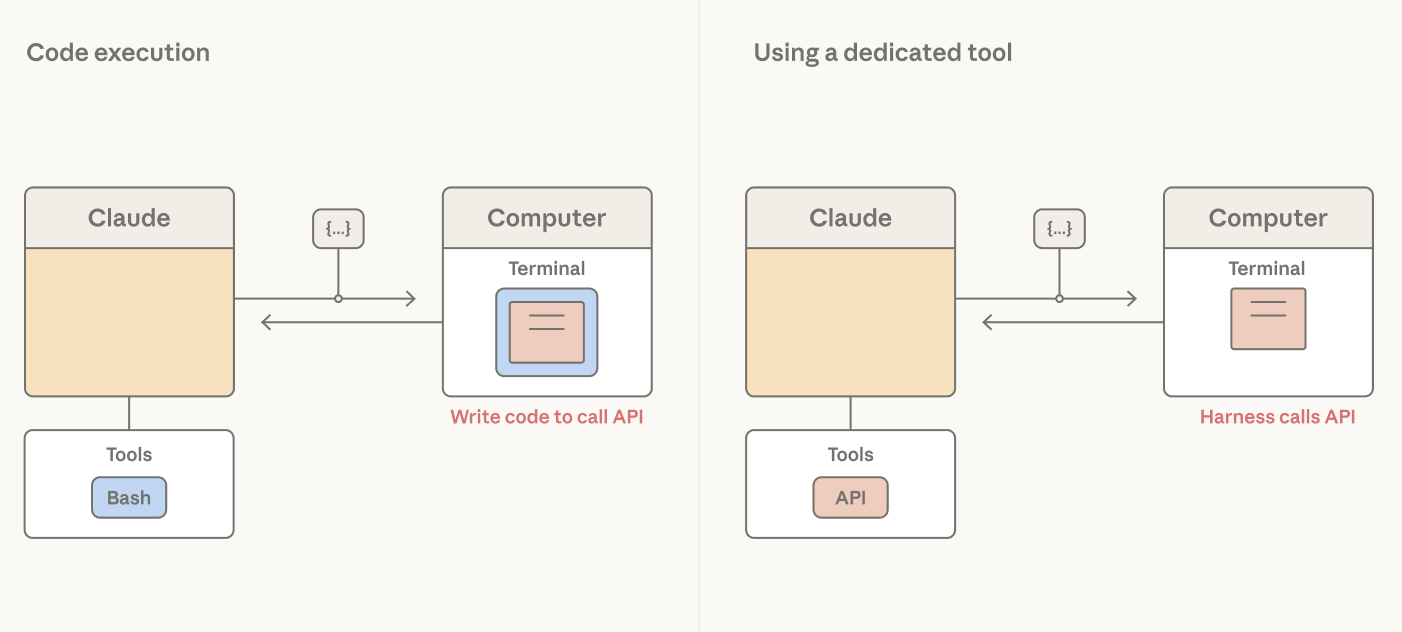
専用ツールは、セキュリティ、UX、可観測性の観点から使える。
ツールは、アクションをユーザーに提示する必要があるときにも役立ちます。たとえば、質問をユーザーに明確に表示するモーダルとしてレンダリングしたり、ユーザーに複数の選択肢を与えたり、ユーザーがフィードバックを提供するまでエージェントループをブロックしたりすることができます。
最後に、ツールは可観測性にも役立ちます。アクションが型付きツールであれば、ハーネスはログ、トレース、リプレイできる構造化された引数を得られます。
アクションをツールに昇格させる決定は、継続的に再評価すべきです。たとえば Claude Code の auto-mode (公開時点でリサーチモード) は、bash ツールの周囲にセキュリティ境界を提供します——別の Claude にコマンド文字列を読ませて安全かどうかを判断させます。このパターンは専用ツールの必要性を 制限 でき、ユーザーが一般的な方向性を信頼しているタスクにのみ使うべきです。それでも、特定の高リスクなアクションでは専用ツールが活躍の場を得られます。
この先を見据えて
Claude の知能のフロンティアは常に変化しています。Claude がそれまでできなかったことへの仮定は、能力のステップチェンジが起こるたびに再テストする必要があります。
私たちはこのパターンが繰り返されるのを見てきました。長期タスク用に作ったエージェントで、Sonnet 4.5 はコンテキスト上限が近づいているのを感じて早めにラップアップしてしまっていました。この「コンテキスト不安」に対処するため、私たちはコンテキストウィンドウをクリアするリセットを追加しました。Opus 4.5 になると、その振る舞いは消えました。補うために作ったコンテキストリセットは、エージェントハーネス内のデッドウェイトになっていたのです。
このデッドウェイトを取り除くことは重要です。というのも、それが Claude のパフォーマンスのボトルネックになり得るからです。時間とともに、アプリケーション内の構造や境界は、次の問いに基づいて剪定されるべきです——私は何をやめられるか?
ここで議論したすべてのツールとパターンを使うには、私たちの claude-api スキルをチェックしてください。
謝辞
Claude Platform チームのテクニカルスタッフメンバーである Lance Martin によって執筆されました。ここで扱ったトピックについて有益な議論をしてくれた Thariq Shihipar、Barry Zhang、Mike Lambert、David Hershey、Daliang Li に特別な感謝を捧げます。編集レビューとフィードバックをくれた Lydia Hallie、Lexi Ross、Katelyn Lesse、Andy Schumeister、Rebecca Hiscott、Jake Eaton、Pedram Navid、Molly Vorwerck にも感謝します。