
マルチエージェント協調パターン: 5つのアプローチとその使い分け
以前の投稿で、マルチエージェントシステムが価値を提供するケースと、シングルエージェントが適しているケースについて考察しました。この投稿は、その判断を下した上で、自分たちの問題にどの協調パターンが合うかを決める必要があるチームのためのものです。
私たちは、目の前の問題に合うかどうかではなく、洗練されて聞こえるかどうかでパターンを選ぶチームを見てきました。まず機能しうる最もシンプルなパターンから始め、どこでつまずくかを観察し、そこから発展させることを推奨します。この投稿では、5つのパターンのメカニクスと限界を検証します。
- Generator-Verifier(生成-検証): 明示的な評価基準を持つ品質重視の出力向け
- Orchestrator-Subagent(オーケストレーター-サブエージェント): 範囲が明確なサブタスクへの明快なタスク分解向け
- Agent Teams(エージェントチーム): 並列で独立した長時間実行サブタスク向け
- Message Bus(メッセージバス): イベント駆動パイプラインと拡大するエージェントエコシステム向け
- Shared State(共有状態): エージェントが互いの発見を積み重ねる共同作業向け
パターン1: Generator-Verifier
これは最もシンプルなマルチエージェントパターンであり、最も多くデプロイされているパターンの一つです。以前の投稿では検証サブエージェントパターンとして紹介しましたが、ここではジェネレーターがオーケストレーターである必要はないため、より広い Generator-Verifier の枠組みを使います。
仕組み
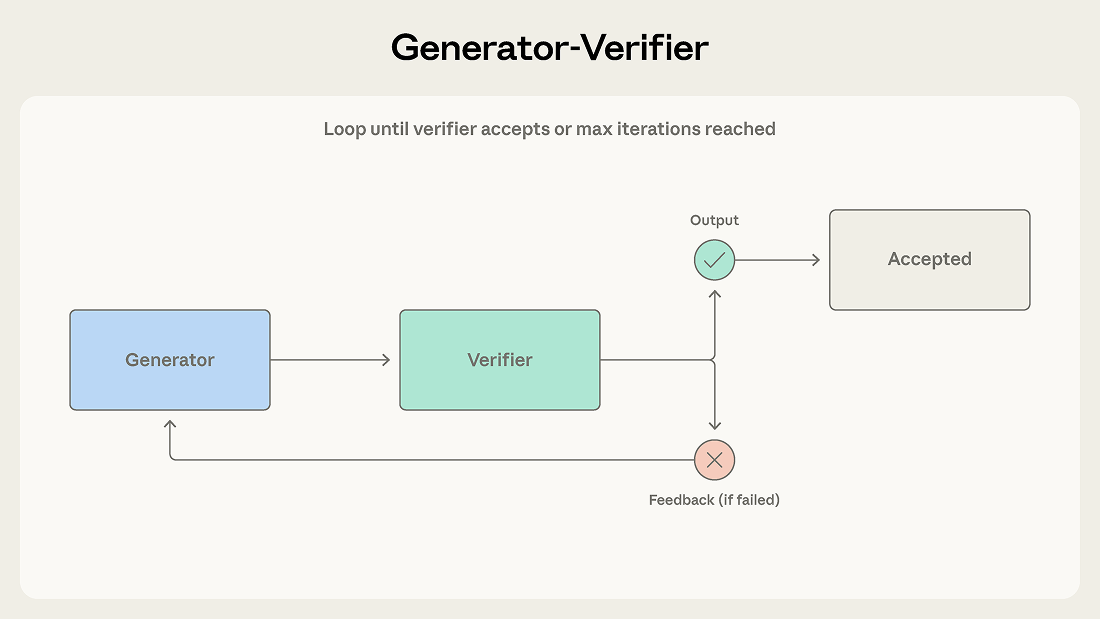
ジェネレーターがタスクを受け取り初期出力を生成し、それをベリファイアに渡して評価させます。ベリファイアは出力が要求された基準を満たしているかを確認し、完了として承認するか、フィードバック付きで却下します。却下された場合、そのフィードバックはジェネレーターに戻され、修正版の生成に使われます。このループは、ベリファイアが出力を承認するか最大反復回数に到達するまで続きます。
うまく機能する場面
カスタマーチケットに対するメール返信を生成するサポートシステムを考えてみましょう。ジェネレーターが製品ドキュメントとチケットのコンテキストを使って初期返信を生成します。ベリファイアはナレッジベースに対する正確性をチェックし、ブランドガイドラインに対するトーンを評価し、提起された各問題に返信が対応しているか確認します。チェックが失敗した場合、具体的な問題を指摘したフィードバック——例えば、間違った料金プランに帰属された機能や、対応されていないチケットの問題など——がジェネレーターに返されます。
出力品質が重要で、評価基準を明示できる場合にこのパターンを使用してください。コード生成(一方のエージェントがコードを書き、もう一方がテストを書いて実行する)、ファクトチェック、ルーブリックベースの採点、コンプライアンス検証、および不正確な出力のコストが追加の生成サイクルのコストを上回るあらゆる領域に有効です。
つまずきやすい場面
ベリファイアの性能はその基準次第です。出力が「良いか」どうかだけを確認するよう指示され、それ以上の基準がないベリファイアは、ジェネレーターの出力をそのまま承認してしまいます。チームが最もよく失敗するのは、検証が何を意味するかを定義せずにループを実装することで、実質を伴わない品質管理の幻想を作り出してしまうケースです(この「早期勝利問題」は以前の投稿で議論しました)。
このパターンはまた、生成と検証が分離可能なスキルであることを前提としています。創造的なアプローチの評価が生成と同じくらい難しい場合、ベリファイアは問題を確実にキャッチできないかもしれません。
最後に、反復ループは停滞する可能性があります。ジェネレーターがベリファイアのフィードバックに対応できない場合、システムは収束せずに振動します。フォールバック戦略(人間にエスカレート、注意書き付きでベストの試行を返すなど)を伴う最大反復回数の制限により、これが無限ループになることを防ぎます。
パターン2: Orchestrator-Subagent
このパターンは階層構造が特徴です。1つのエージェントがチームリーダーとして作業を計画し、タスクを委任し、結果を統合します。サブエージェントは特定の責務を処理して報告を返します。
仕組み
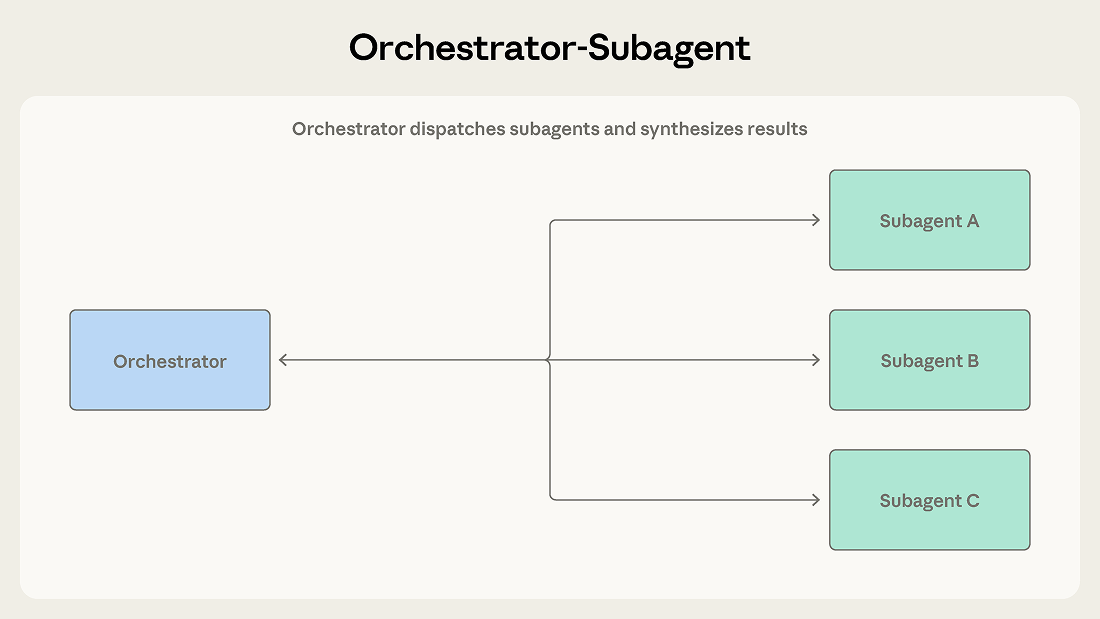
リードエージェントがタスクを受け取り、アプローチ方法を決定します。一部のサブタスクは直接処理し、他をサブエージェントにディスパッチすることもあります。サブエージェントは作業を完了して結果を返し、オーケストレーターがそれを最終出力に統合します。
Claude Code はこのパターンを使用しています。メインエージェントが自らコードを書き、ファイルを編集し、コマンドを実行しつつ、大規模なコードベースの検索や独立した問題の調査が必要な場合にバックグラウンドでサブエージェントをディスパッチし、結果がストリーミングで返される間も作業を続けます。各サブエージェントは独自のコンテキストウィンドウで動作し、要約された発見事項を返します。これにより、オーケストレーターのコンテキストは主要なタスクに集中したまま、探索が並行して進行します。
うまく機能する場面
自動コードレビューシステムを考えてみましょう。プルリクエストが到着すると、セキュリティ脆弱性のチェック、テストカバレッジの検証、コードスタイルの評価、アーキテクチャの一貫性の評価が必要です。各チェックは独立しており、異なるコンテキストを必要とし、明確な出力を生成します。オーケストレーターが各チェックを専門のサブエージェントにディスパッチし、結果を収集して統一されたレビューに統合します。
タスク分解が明確でサブタスク間の相互依存が少ない場合にこのパターンを使用してください。オーケストレーターが全体目標の一貫したビューを維持しつつ、サブエージェントは特定の責務に集中します。
つまずきやすい場面
オーケストレーターが情報のボトルネックになります。あるサブエージェントが別のサブエージェントの作業に関連する何かを発見した場合、その情報はオーケストレーターを経由して戻る必要があります。セキュリティサブエージェントがアーキテクチャサブエージェントの分析に影響する認証の欠陥を発見した場合、オーケストレーターはこの依存関係を認識して適切に情報をルーティングしなければなりません。そのようなハンドオフが繰り返されると、重要な詳細が失われたり要約されて消えたりすることがよくあります。
逐次実行もスループットを制限します。明示的に並列化しない限り、サブエージェントは1つずつ実行されるため、マルチエージェントのトークンコストを負いながら速度の利点は得られません。
パターン3: Agent Teams
作業が長時間にわたり独立して進行できる並列サブタスクに分解される場合、Orchestrator-Subagent は不必要に制約的になることがあります。
仕組み
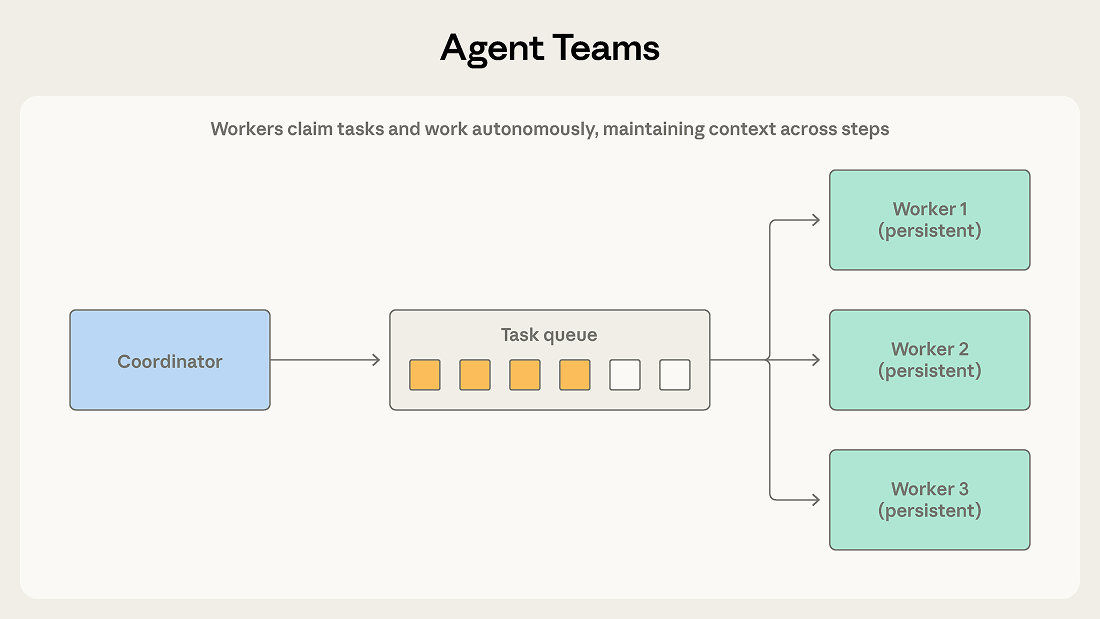
コーディネーターが複数のワーカーエージェントを独立したプロセスとして生成します。チームメイトは共有キューからタスクを取得し、複数のステップにわたって自律的に作業し、完了を通知します。
Orchestrator-Subagent との違いはワーカーの持続性です。オーケストレーターは1つの限定されたサブタスクのためにサブエージェントを生成し、サブエージェントは結果を返した後に終了します。チームメイトは多くの割り当てにわたって存続し、コンテキストとドメインの専門性を蓄積して、時間とともにパフォーマンスを向上させます。コーディネーターは作業を割り当て結果を収集しますが、タスク間でワーカーをリセットしません。
うまく機能する場面
大規模なコードベースをあるフレームワークから別のフレームワークに移行することを考えてみましょう。チームメイトは各サービスを独立して移行できます。それぞれ独自の依存関係、テストスイート、デプロイ設定を持っています。コーディネーターが各サービスをチームメイトに割り当て、各チームメイトが自律的に移行を進めます。依存関係の更新、コード変更、テスト修正、検証。コーディネーターは完了した移行を収集し、システム全体の統合テストを実行します。
サブタスクが独立しており、持続的な複数ステップの作業から恩恵を受ける場合にこのパターンを使用してください。各チームメイトはワンショットのディスパッチでは再現できない方法で、担当ドメインに関するコンテキストを構築します。
つまずきやすい場面
独立性が重要な要件です。Orchestrator-Subagent ではオーケストレーターがサブエージェント間を仲介して情報をルーティングできますが、チームメイトは自律的に動作し、中間的な発見を簡単に共有できません。あるチームメイトの作業が別のチームメイトに影響を与えても、どちらもそれを認識しておらず、出力が矛盾する可能性があります。
完了検知も難しくなります。チームメイトは可変期間にわたって自律的に作業するため、コーディネーターは部分的な完了を処理する必要があります。あるチームメイトが2分で完了し、別のチームメイトが20分かかるケースです。
共有リソースは両方の問題を複合させます。複数のチームメイトが同じコードベース、データベース、またはファイルシステムで作業する場合、2つのチームメイトが同じファイルを編集したり、互換性のない変更を加えたりする可能性があります。このパターンには慎重なタスク分割と競合解決メカニズムが必要です。
パターン4: Message Bus
エージェント数が増加しインタラクションパターンが複雑になると、直接的な協調の管理が困難になります。メッセージバスは、エージェントがイベントをパブリッシュしサブスクライブする共有コミュニケーション層を導入します。
仕組み
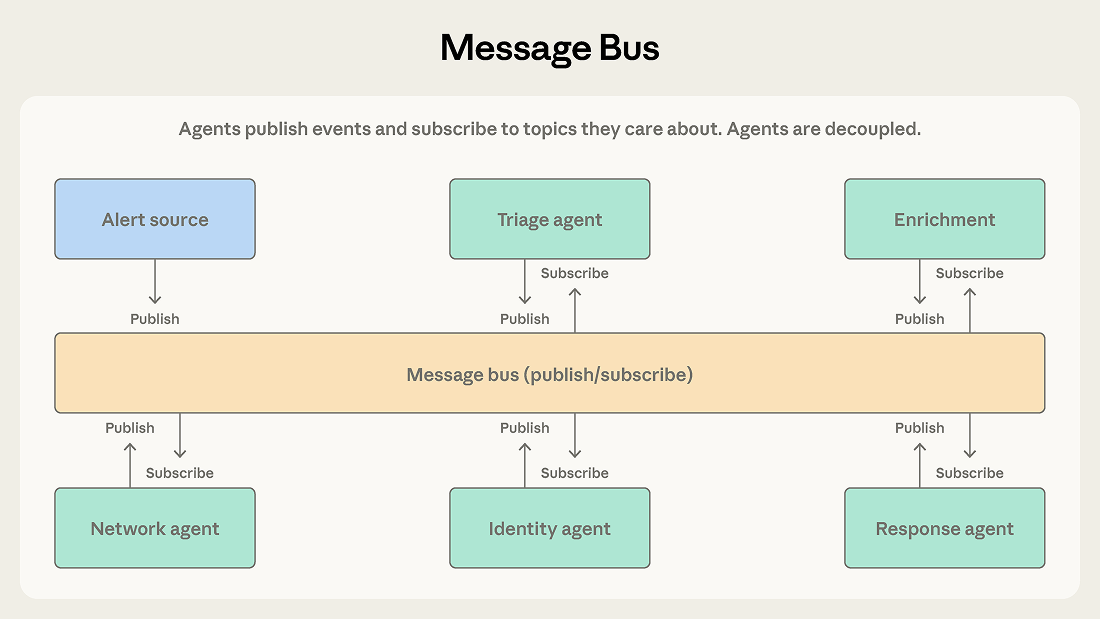
エージェントはパブリッシュとサブスクライブの2つのプリミティブを通じてインタラクションします。エージェントは関心のあるトピックをサブスクライブし、ルーターがマッチするメッセージを配信します。新しい能力を持つ新しいエージェントは、既存の接続を変更することなく関連する作業の受信を開始できます。
うまく機能する場面
セキュリティオペレーション自動化システムがこのパターンの強みを示します。アラートが複数のソースから到着し、トリアージエージェントが各アラートを重大度とタイプで分類して、高重大度のネットワークアラートをネットワーク調査エージェントに、認証情報関連のアラートをIDアナリシスエージェントにルーティングします。各調査エージェントはコンテキスト収集エージェントが処理するエンリッチメントリクエストをパブリッシュすることがあります。発見事項は適切なアクションを決定するレスポンスコーディネーションエージェントに流れます。
このパイプラインがメッセージバスに適しているのは、イベントがあるステージから次のステージに流れること、脅威カテゴリの進化に応じてチームが新しいエージェントタイプを追加できること、そしてチームがエージェントを独立して開発・デプロイできることによります。
ワークフローが事前に決められたシーケンスではなくイベントから生まれるイベント駆動パイプラインで、エージェントエコシステムが成長する可能性がある場合にこのパターンを使用してください。
つまずきやすい場面
イベント駆動コミュニケーションの柔軟性はトレーシングを困難にします。アラートが5つのエージェントにわたってイベントのカスケードをトリガーした場合、何が起こったかを理解するには慎重なログ記録と相関が必要です。デバッグは、オーケストレーターの逐次的な決定を追跡するよりも困難です。
ルーティングの精度も重要です。ルーターがイベントを誤分類したりドロップしたりすると、システムはサイレントに失敗します——何も処理しないが、クラッシュもしない。LLMベースのルーターはセマンティックな柔軟性を提供しますが、独自の障害モードを導入します。
パターン5: Shared State
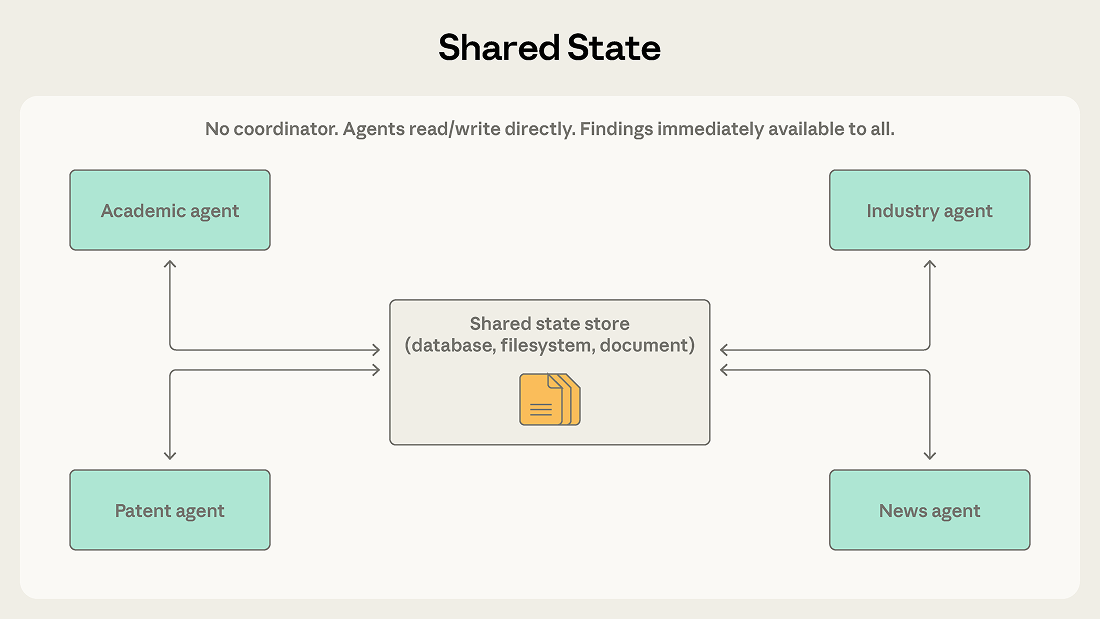
前のパターンにおけるオーケストレーター、チームリーダー、メッセージルーターはすべて情報フローを中央で管理します。Shared State は仲介者を排除し、すべてのエージェントが直接読み書きできる永続ストアを通じてエージェントが協調できるようにします。
仕組み
エージェントは自律的に動作し、共有データベース、ファイルシステム、またはドキュメントの読み書きを行います。中央のコーディネーターはいません。エージェントはストアで関連する情報を確認し、発見したものに基づいて行動し、自分の発見事項をストアに書き戻します。作業は通常、初期化ステップが質問やデータセットをストアに投入することで開始され、終了条件が満たされたときに終了します。時間制限、収束閾値、またはストアに十分な回答が含まれていると判断する指定エージェントなどです。
うまく機能する場面
複数のエージェントが複雑な質問のさまざまな側面を調査するリサーチ統合システムを考えてみましょう。1つは学術文献を探索し、別の1つは業界レポートを分析し、3つ目は特許出願を調べ、4つ目はニュース報道をモニターします。各エージェントの発見が他のエージェントの調査に影響を与える可能性があります。学術文献エージェントが重要な研究者を発見し、その研究者の会社を業界エージェントがより詳細に調べるべきかもしれません。
Shared State では、発見事項は直接ストアに入ります。業界エージェントは、コーディネーターが情報をルーティングするのを待つことなく、学術エージェントの発見をすぐに確認できます。エージェントは互いの作業の上に構築し、共有ストアは進化するナレッジベースになります。
Shared State はまた、コーディネーターを単一障害点として排除します。いずれかのエージェントが停止しても、他のエージェントは読み書きを続けます。Orchestrator やメッセージバスのシステムでは、コーディネーターやルーターの障害がすべてを停止させます。
つまずきやすい場面
明示的な協調がないため、エージェントは作業を重複したり矛盾するアプローチを追求したりする可能性があります。2つのエージェントが独立して同じリードを調査するかもしれません。エージェントのインタラクションはトップダウン設計ではなくシステム動作を生み出すため、結果の予測が難しくなります。
より困難な障害モードはリアクティブループです。例えば、Agent A が発見を書き込み、Agent B がそれを読んでフォローアップを書き込み、Agent A がそのフォローアップを見て応答する。システムは収束しない作業にトークンを消費し続けます。作業の重複と同時書き込みには既知のエンジニアリング上の修正(ロック、バージョニング、パーティショニング)がありますが、リアクティブループは動作上の問題であり、ファーストクラスの終了条件が必要です。時間予算、収束閾値(Nサイクルで新しい発見がない)、またはストアに十分な回答が含まれているかどうかを判断する専任のエージェントなどです。終了を後付けとして扱うシステムは、際限なくサイクルするか、あるエージェントのコンテキストが一杯になったときに恣意的に停止する傾向があります。
パターンの選択と発展
適切なパターンは、システムに関するいくつかの構造的な問いに依存します。以前の投稿では、作業の種類ではなく各エージェントが必要とするコンテキストに基づいて作業を分割するコンテキスト中心の分解を主張しました。その原則はここでも適用されます。各パターンはコンテキストの境界と情報フローの管理方法が異なります。
Orchestrator-Subagent と Agent Teams の比較
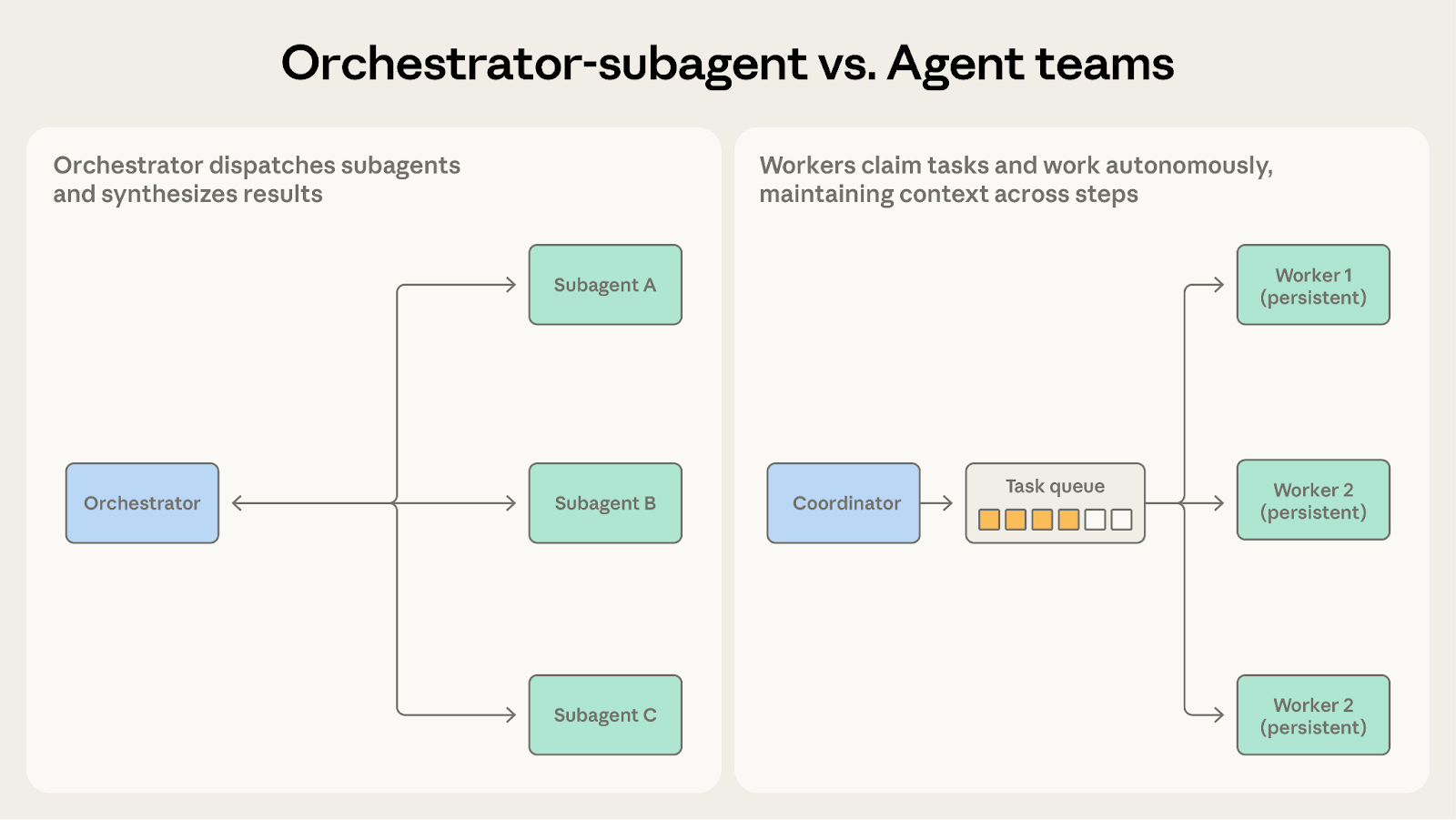
どちらもコーディネーターが他のエージェントに作業をディスパッチします。問いは、ワーカーがどの程度の期間コンテキストを維持する必要があるかです。
- Orchestrator-Subagent を選ぶ場合: サブタスクが短く、集中的で、明確な出力を生成する場合。コードレビューシステムはここでうまく機能します。各チェックは分析を実行し、レポートを生成し、単一の限定された呼び出し内で返されるためです。サブエージェントは複数のサイクルにわたってコンテキストを保持する必要がありません。
- Agent Teams を選ぶ場合: サブタスクが持続的な複数ステップの作業から恩恵を受ける場合。コードベース移行はここに適しています。各チームメイトが担当サービスに関する実質的な知識を蓄積するためです。依存関係グラフ、テストパターン、デプロイ設定。その蓄積されたコンテキストは、ワンショットのディスパッチでは再現できない方法でパフォーマンスを向上させます。
サブエージェントが呼び出しをまたいで状態を保持する必要がある場合、Agent Teams がより適しています。
Orchestrator-Subagent と Message Bus の比較
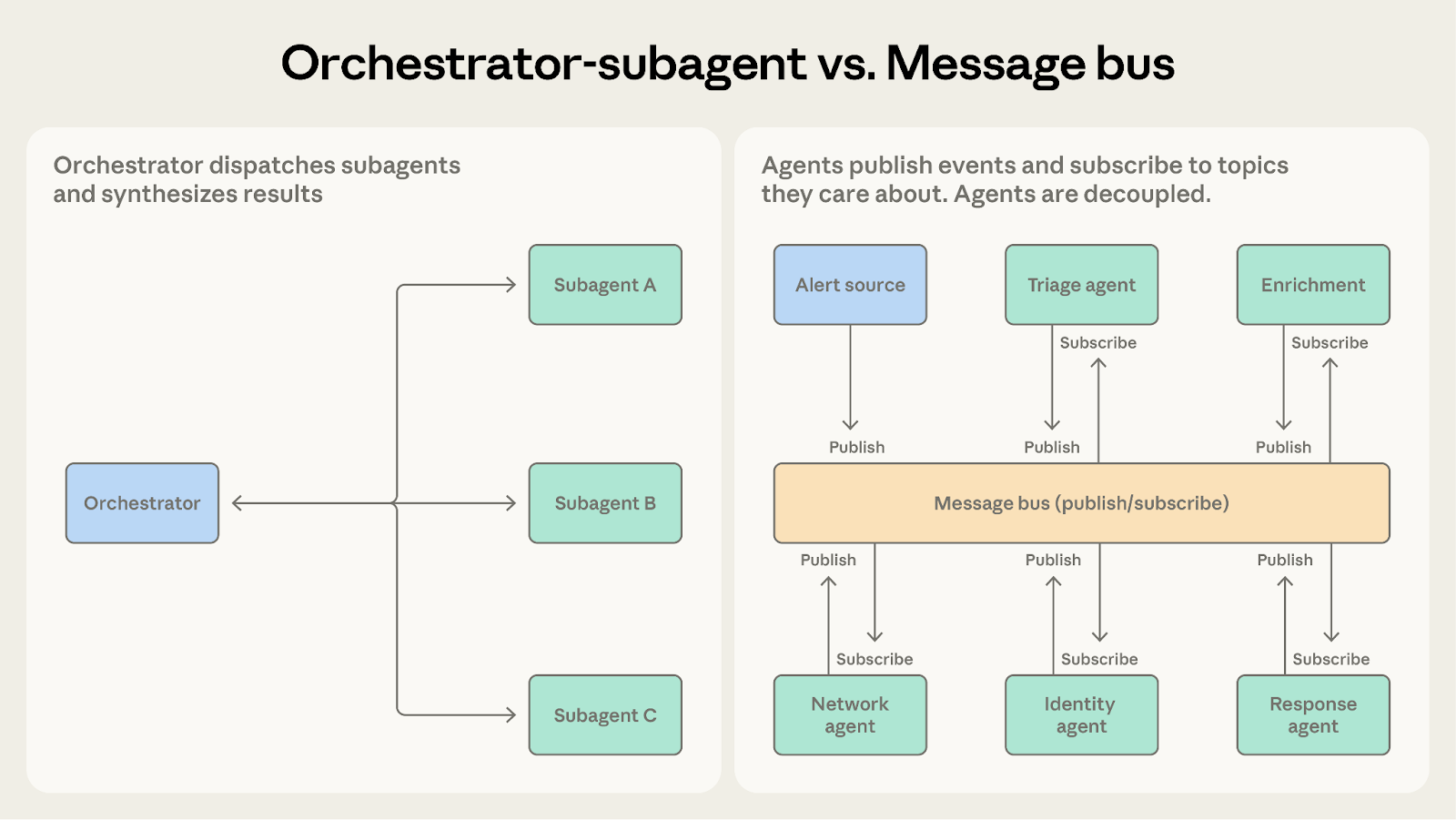
どちらもマルチステップのワークフローを処理できます。問いは、ワークフロー構造がどの程度予測可能かです。
- Orchestrator-Subagent を選ぶ場合: ステップのシーケンスが事前に分かっている場合。コードレビューシステムは固定のパイプライン(PR を受け取り、チェックを実行し、結果を統合する)に従います。
- Message Bus を選ぶ場合: ワークフローがイベントから生まれ、発見されたものに応じて変化する可能性がある場合。セキュリティオペレーションシステムはどのアラートが到着するか、どの調査パスが必要になるかを予測できません。新しいアラートタイプが出現し、新しい処理が必要になるかもしれません。メッセージバスは、事前に決められたシーケンスに従うのではなく、対応可能なエージェントにイベントをルーティングすることでその変動性に対応します。
多様なケースを処理するためにオーケストレーターに条件ロジックが蓄積されてくると、メッセージバスはそのルーティングを明示的かつ拡張可能にします。
Agent Teams と Shared State の比較
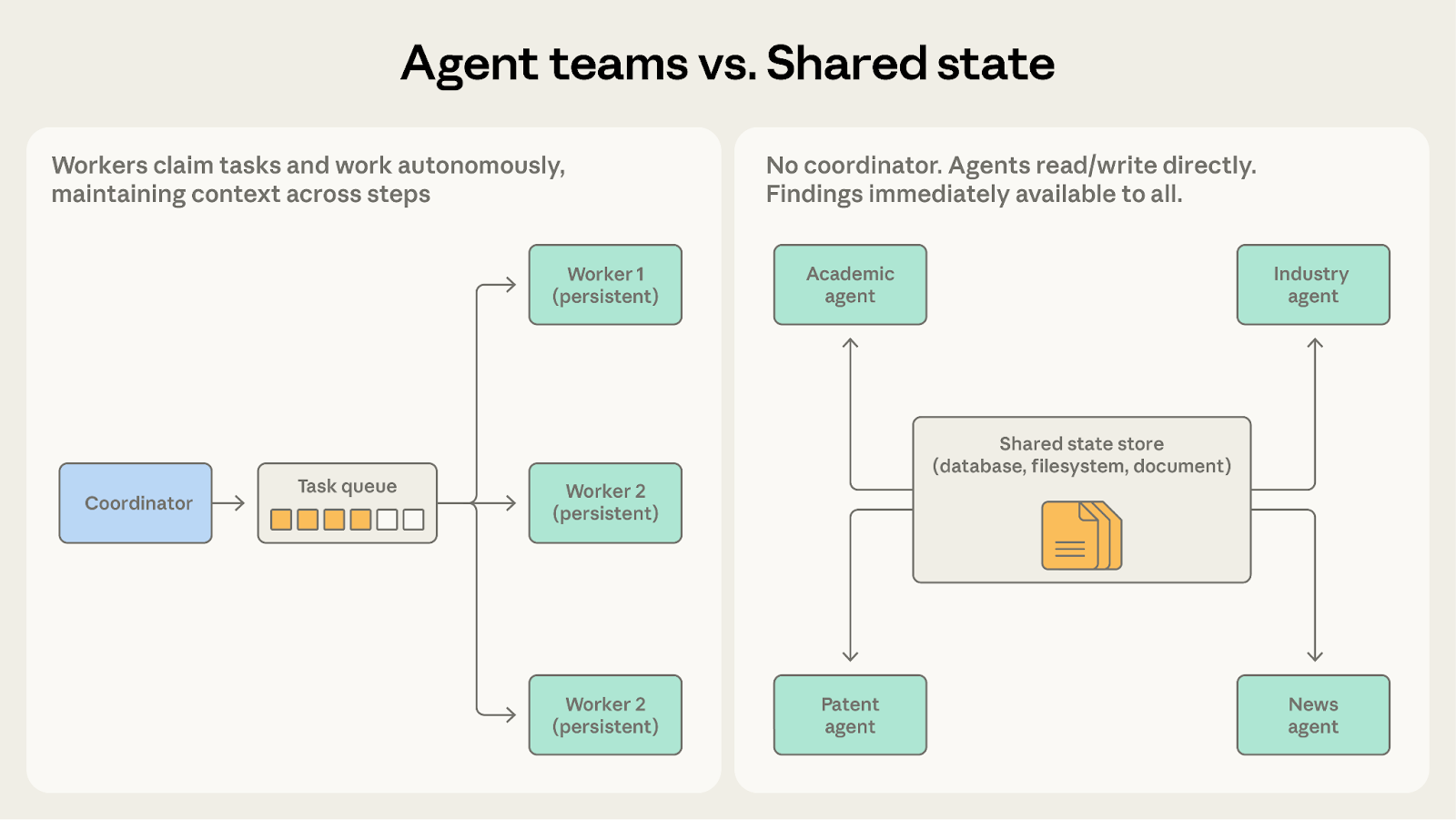
どちらもエージェントが自律的に作業します。問いは、エージェントが互いの発見を必要とするかどうかです。
- Agent Teams を選ぶ場合: エージェントがインタラクションのない別々のパーティションで作業する場合。コードベース移行はここに適しています。各チームメイトが自分のサービスを処理し、コーディネーターが最後に結果を組み合わせるためです。
- Shared State を選ぶ場合: エージェントの作業が協調的で、発見がリアルタイムで相互に流れるべき場合。リサーチ統合システムがより適しています。学術エージェントが重要な研究者を発見すると、それが即座に業界エージェントの調査に関連するものになるためです。
チームメイトが最終結果の共有だけでなく互いにコミュニケーションする必要が出てきたら、Shared State のほうがより自然です。
Message Bus と Shared State の比較
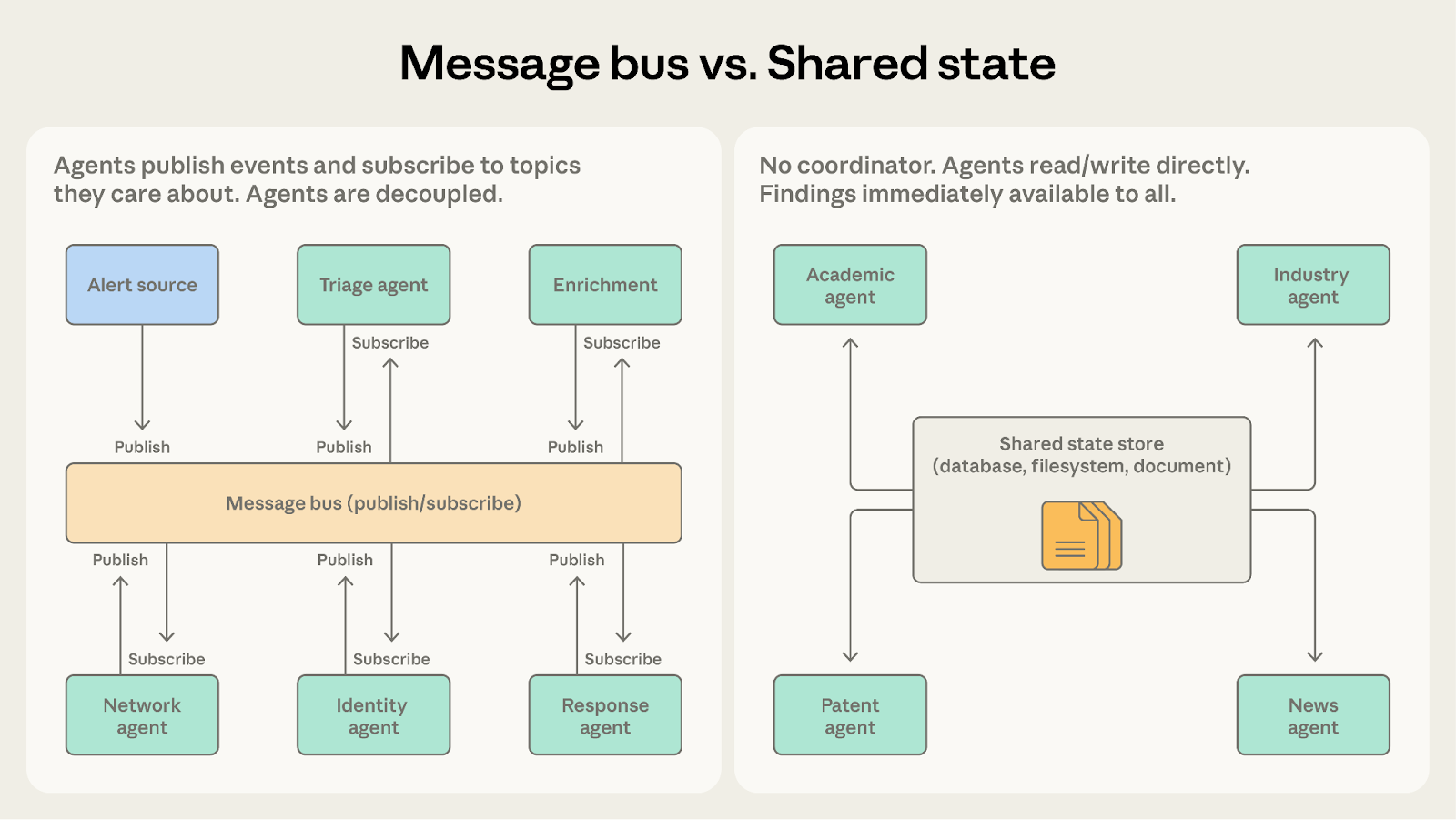
どちらも複雑なマルチエージェント協調をサポートします。問いは、作業が離散イベントとして流れるか、共有ナレッジベースに蓄積されるかです。
- Message Bus を選ぶ場合: エージェントがパイプラインでイベントに反応する場合。セキュリティオペレーションシステムはアラートをステージごとに処理し、各イベントが完了前に次のイベントをトリガーします。このパターンはイベントを対応可能なエージェントにルーティングすることに効率的です。
- Shared State を選ぶ場合: エージェントが時間をかけて蓄積された発見の上に構築する場合。リサーチ統合システムは知識を継続的に収集します。エージェントは繰り返しストアに戻り、他のエージェントが発見したものを確認して調査を調整します。
メッセージバスにはまだルーターがあり、イベントの行き先を中央のコンポーネントが決定することを意味します。Shared State は分散型です。単一障害点の排除が優先事項であれば、Shared State がそれをより完全に提供します。
メッセージバスシステムのエージェントが、アクションをトリガーするためではなく発見を共有するためにイベントをパブリッシュしている場合、Shared State のほうが適しています。
始め方
本番システムはパターンを組み合わせることが多いです。一般的なハイブリッドは、全体のワークフローに Orchestrator-Subagent を使い、協調が多いサブタスクに Shared State を使うものです。別のハイブリッドは、イベントルーティングに Message Bus を使い、各イベントタイプの処理に Agent Teams スタイルのワーカーを使います。これらのパターンはビルディングブロックであり、相互に排他的な選択ではありません。
以下の表は、各パターンが適切な場面をまとめたものです。
| 状況 | パターン |
|---|---|
| 品質重視の出力、明示的な評価基準 | Generator-Verifier |
| 明快なタスク分解、範囲が明確なサブタスク | Orchestrator-Subagent |
| 並列ワークロード、独立した長時間実行サブタスク | Agent Teams |
| イベント駆動パイプライン、成長するエージェントエコシステム | Message Bus |
| 共同リサーチ、エージェントが発見を共有 | Shared State |
| 単一障害点の排除が必要 | Shared State |
ほとんどのユースケースでは、Orchestrator-Subagent から始めることを推奨します。最も少ない協調オーバーヘッドで最も広い範囲の問題を処理できます。どこでつまずくかを観察し、特定のニーズが明確になるにつれて他のパターンに発展させてください。
今後の投稿では、各パターンを本番実装やケーススタディとともに詳しく検証します。マルチエージェントシステムにいつ投資する価値があるかの背景については、Building multi-agent systems: when and how to use them をご覧ください。
謝辞
Cara Phillips が執筆し、Eugene Yang、Jiri De Jonghe、Samuel Weller、Erik Schluntz が寄稿しました。